 Slowcontrol - main
Slowcontrol - main 
Frequently asked questions for the LEM experiment
Here you might find some of your questions answered:
- General Questions
- What to do when changing from "B-parallel" to "B-perpendicular" (WEW magnet) setup?
- How to change a Sample?
- What is a good He flow value for the sample cryostate for a given temperature?
- I want to use the ramping feature of the autorun TEMP command to warm/cool the sample temperature. Are there any critical issues?
- The temperature of the sample cryostat shows oscillating behaviour. What can I do?
- After a sample temperature change the sample region high voltages are not really ramped back. What is wrong?
- While trying to ramp the sample region HV's up, the hang at around 3.5kV, not exceeding this value. What is wrong?
- From where do I get the necessary passwords?
- How to change the angle of the electrostatic Mirror?
- What is the calibration of the WEW magnet (B-perpendicular setup)?
- What is the calibration for the B-parallel magnet?
- How can I convert and/or copy the data ?
- Can I be notified by SMS or E-Mail if something is going wrong with the measurement ?
- Get the warning: HV tripped due to too high rate (TD=1300076/trip level=1000000). What needs to be done?
- For the Bpar/Danfysik setup: what is the best ring anode steering for a given field?
- For the Bpar/Danfysik setup: Is alpha = 1 centering the beam?
- For the Bpar/Danfysik setup: What is the precessing background for a 20x20 mm2 sample?
- How are the horizontal low-energy muon spin angles defined?
- Auto Run related Questions
- Beamline related Questions
- How to start muE4 beam line control?
- How to switch on muE4 beam power supplies remotely?
- How to set LE-mu transport potentials (HV's)?
- How to determine the LE-mu implantation energy?
- How to restart beamline power supplies manually?
- What are 'normal' detector and event rates?
- Which E-target was used in LE-uSR runs?
- How do LEM rates change as a function of p-beam position on Target E?
- How do the LEM beam spot and alpha parameter change as a function of RA steering?
- General Midas related Questions
- Slowcontrol related Questions
- A slow control frontend connected to the RS232 terminal server does not to respond even after restart. What can I do?
- How to logout a blocking port at the RS232 terminal server?
- How to check an MSCB line without Midas?
- How to deal with a hanging MSCB submaster?
- How to remotely repower some of the slowcontrol equipment using lemplug?
- How to remotely set the needlevalve of the transferline?
- Online Analysis related Questions
- How to view LE-uSR runs?
- How to convert LE-uSR data for WKM, MaxEnt, Wimda?
- Where are the data files?
- Where are the input files for WKM and MaxEnt?
- From where do I get the t0's?
- What is the time resolution of the TDC?
- How can WKM read *.root files?
- How to estimate alpha, how to check goodness of data?
- DAQ related Questions
- Analyzer related Questions
- Analysis Software related Questions
What to do when changing from "B-parallel" to "B-perpendicular" (WEW magnet) setup?
- check this elog entry.
How to change a Sample?
A detailed description can be found here: SampleChange
Important note (for internal use only): in case the sample cryo has been changed, also change it for the midas system via ConfigSetup on the main experiment webpage (see also SampleChange).
In order that the whole update procedure works, the 'SampleCryo' frontend needs to be running, furthermore any typo in the name will prevent the procedure to work. For more details see SampleChange.
What is a good He flow value for the sample cryostate for a given temperature?
Each used cryostate for the LEM experiment has slightly different He flow values for given temperature, therefore the will be discussed seperatly here.
Cryo Konti-1
For the He flow (BH Flow setpoint) there is a very simple relationship between temperature and good He flow:
![\[\mathrm{flow} = (1.0\cdot 10^5 / \mathrm{temperature~setpoint}) + 300.\]](form_0.png)
In order that this is working properly, the manual needle valve at the transfer line needs to be set properly. If not, you will notice flow and temperature oscillations. For temperature greater or about 10 K an opening of about 0.15-0.3 (turns starting from the closed position, indicated by the scale on the turning nob of the needle valve) should be fine. For lower temperature it has to be found experimentally.
Cryo Konti-2
For the He flow (BH Flow setpoint) there is a very simple relationship between temperature and good He flow:
In order that this is working properly, the needle valve at the transfer line needs to be set properly. If not, you will notice flow and temperature oscillations. If you are not running lemAutoRun, you can adjust the needle valve position via the needle valve setting in the sample-cryo frontend.
Cryo Konti-3
To be written yet ...
Cryo LowTemp-1
To be written yet ...
Cryo LowTemp-2
To be written yet ...
I want to use the ramping feature of the autorun TEMP command to warm/cool the sample temperature. Are there any critical issues?
Yes, there are! The first and upmost important is that you shouldn't use ramping speeds greater than 5K/min, both, for cooling as well as for warming up. Another important rule of thumb is that the StabilityTimeout constant of the TEMP autoRun command should follow this equation
StabilityTimeout > 120 (Tstart[K] - Tend[K]) / ramping[K/min],
otherwise it is likely that the end temperature Tend is not reached within the timeout. A more detailed description can be found in the lemAutoRun manual and/or here.
The temperature of the sample cryostat shows oscillating behaviour. What can I do?
Have you set the He flow properly? See Cryo Konti-1, if the flow is set properly, most probably the manual needle valve at the LHe transfer line is not. The get rid of these temperature and flow oscillations you need to either slightly open or close it. For the electric needlevalves see How to remotely set the needlevalve of the transferline?
After a sample temperature change the sample region high voltages are not really ramped back. What is wrong?
What can happen when increasing the sample temperature too fast is that the pressure in the sample chamber is exceeding a level of 1.0e-6 mbar. At this level the high voltage (HV) interlock will fire switching off the power of the HV power supplies in the sample region (FUG: Sample, Sample_G1, Sample_G2, RA-R, RA-L). What to do? If the pressure condition is OK again, i.e. p < 1.0e-6 mbar, the sample HV interlock needs to be rested manually. The HV interlock for the FUG HV power supply of the sample chamber is found on top of the sample temperature controller (see also SampleChange where there is a picture of the sample HV interlock). By dipping the dip switch, the power of the FUG HV power supplies will come back, and the HV can be ramped back.
While trying to ramp the sample region HV's up, the hang at around 3.5kV, not exceeding this value. What is wrong?
Most likely the sample region HV interlock was activated or not reseted after a sample change. This is leading to this puzzling behaviour. Since the FUG HV power supplies (used for the HV's) are analogly actuated, this can feign HV ramping, though the HV power supplies are actually off! This fake ramping is up to seemingly 3.5kV possible. So if you have any doubts: check the sample HV interlock (are any other HV interlock for the FUG's).
From where do I get the necessary passwords?
The experiment responsable will give you the necessary passwords at the beginning of your beamtime.
How to change the angle of the electrostatic Mirror?
Adjustment of Mirror angle: if you want to increase the angle (from 295.5 at the nonius to 296 degree, for example), you can do it without any precaution (except shutting down HV). If you want to go from 295.5 to 295 degree, first go to a smaller angle (290 degree, for example) and then increase to 295 in order to account for the mechanical slip.
What is the calibration of the WEW magnet (B-perpendicular setup)?
The magnet field B (in Gauss) is given by the WEW current I (in A):
B = 0.866 + 5.702 * I,
or
I = 0.1754 * B - 0.1519.
A few values:
| Field (G) | Current (A) |
|---|---|
| 50.0 | 8.62 |
| 100.0 | 17.39 |
| 150.0 | 26.16 |
| 200.0 | 34.93 |
| 250.0 | 43.70 |
Remanent field after running degauss_bruker: Bx=By=0.01 G, Bz=-0.08 G.
What is the calibration for the B-parallel magnet?
The magnetic field B (in Gauss) of the B-parallel magnet at the sample position is related to the current I (in A) through the magnet as
B = 1.63 + 32.376 * I,
or
I = 0.030887 * B - 0.050346.
A few values:
| Field (G) | Current (A) |
|---|---|
| 50.0 | 1.49 |
| 100.0 | 3.04 |
| 150.0 | 4.58 |
| 200.0 | 6.13 |
| 250.0 | 7.67 |
Remanent field after running degauss_danfysik: Bx=0.01 G, By=-0.17G, Bz=0.12 G.
How can I convert and/or copy the data ?
The data of the low energy muon experiment are stored in *.root files. The .root file is written every 5 minutes, so that it contains also the data of the active run. The online view programs and the online data analysis (e.g. WKM) are able to read these files.
The *.root files can be converted into
- psi binary files psibin
- nemu files nemu
- ascii files ascii
- mud files (triumf format) mud
by the program root2many.
The commandline for this program reads:
root2many file_type runnumber [-postpileup] [-y##] [-rebin ##]
where
-
file_typeis one of the type mentioned above in bold-face -
runnumbercan be a- single number
- a series of numbers seperated by spaces, in which case the runs are added before being converted
-
two numbers separated by the word to, like
1812to1824, in which the case the files 1812 until and including 1824 will be converted.
-
adding the option
-postpileupresults in converting the post_pile_up corrected histograms. -
the year of the measurement can be set by eq
-y06. If omitted, the present year will be used. -
the data can be rebinned before converting (note that one histogram contains 61000 points) by adding e.g.
-rebin 10causing groups of 10 data points being added into a new bin. Note that because of the structure of the PSIBIN and MUD data files there will be always a rebinning such that the histogram length is smaller than 32000.
Acknowledgement The conversion to mud file is done by calling mud_utils from TRIUMF
Can I be notified by SMS or E-Mail if something is going wrong with the measurement ?
If the Midas data acquisition system registers an alarm condition an alarm notification can be sent by SMS and/or e-mail. Follow the instruction given in this elog entry to activate alarm notification and to change the SMS and/or e-mail address.
Get the warning: HV tripped due to too high rate (TD=1300076/trip level=1000000). What needs to be done?
Explanation: the LEM transport setting is protecting itself from too high trigger detector rates (TD rates). If the TD rate is above a given threshold (typically 1e6) it will shutdown the HV's of the LEM transport system (HV FUG). An ongoing run will be paused immediately.
How should one proceed if this is happening? First try to ramp the FUG HV's gradually back to where they were before the trip. Keep an eye on the TD rate, otherwise you will start all over again faster than you think. If the FUG HV's are ramped back and the TD rates are OK, just resume the paused run. If you cannot get the FUG HV's ramped back without causing HV trips something is wrong and you should call your local contact.
Note: It might happen that you get a TD HV trip during an autorun sequence when NO run is active, e.g. when changing the temperature. In this case, lemAutoRun will not go on with its sequence as long as the warning (red bar with a message as in the title of this FAQ) is active. However, as soon as you reset the warning, the system is assuming that you have resolved the problem and will go on. Hence, best practice is first to fix the problem, and only than reset the warning!
For the Bpar/Danfysik setup: what is the best ring anode steering for a given field?
The following table is showing you optimal ring anode (RA) steerings for a given field (15kV Transport settings only, sorry):
| B (G) (I (A)) | E (keV) | RAL (kV) | RAR (kV) | RAT/RAB (kV) | RAL-RAR (kV) |
|---|---|---|---|---|---|
| 95.1 (3.03) | 2.0 | 10.396 | 10.724 | 10.56 | -0.328 |
| 95.1 (3.03) | 4.0 | 10.405 | 10.715 | 10.56 | -0.310 |
| 95.1 (3.03) | 6.0 | 10.426 | 10.694 | 10.56 | -0.268 |
| 95.1 (3.03) | 10.0 | 10.422 | 10.698 | 10.56 | -0.276 |
| 95.1 (3.03) | 20.0 | 10.435 | 10.685 | 10.56 | -0.250 |
| 144.6 (4.57) | 2.0 | 10.248 | 10.872 | 10.56 | -0.624 |
| 144.6 (4.57) | 4.0 | 10.257 | 10.864 | 10.56 | -0.607 |
| 144.6 (4.57) | 6.0 | 10.2755 | 10.8435 | 10.56 | -0.568 |
| 144.6 (4.57) | 10.0 | 10.2965 | 10.8235 | 10.56 | -0.527 |
| 144.6 (4.57) | 20.0 | 10.3035 | 10.8165 | 10.56 | -0.513 |
| 258.5 (8.08) | 2.0 | 9.822 | 11.298 | 10.56 | -1.476 |
| 258.5 (8.08) | 4.0 | 9.819 | 11.301 | 10.56 | -1.482 |
| 258.5 (8.08) | 6.0 | 9.819 | 11.301 | 10.56 | -1.482 |
| 258.5 (8.08) | 10.0 | 9.839 | 11.281 | 10.56 | -1.442 |
| 258.5 (8.08) | 20.0 | 9.8705 | 11.2495 | 10.56 | -1.379 |
For fields different from the ones given in the table use the following formula:
![\[ \mathrm{RAL-RAR\, (V)} = 2.13 - 1.787 B\, \mathrm{(G)} - 0.01449 B^2\, \mathrm{(G^2)} \]](form_1.png)
and for the implantation energy fine tuning Fig.4 Bottom of the memo Ag 20 x 20 mm2 on a Ni Sample Plate.
For details see the memo Ag 20 x 20 mm2 on a Ni Sample Plate.
For the Bpar/Danfysik setup: Is alpha = 1 centering the beam?
Unfortunately not for the current setup! The reason is that the positron counter positioning is not very reproducable. If you need proper values for the ring anode steering see For the Bpar/Danfysik setup: what is the best ring anode steering for a given field?.
For the Bpar/Danfysik setup: What is the precessing background for a 20x20 mm2 sample?
As precessing background is understood muons precessing at Bext, i.e. they missed the sample but stopped on the Ag coated Al sample plate. This precessing background depends on Bext and the implantation energy E. For proper ring anode steerings some estimates can be found in the memo Ag 20 x 20 mm2 on a Ni Sample Plate, Table 2 and Figure 5.
How are the horizontal low-energy muon spin angles defined?
See the following e-log entry. For the Bpar setup, the maximal transmission is given for -45 degree spin rotation. If working with a spin rotation angle of -10 degree, the spin rotator is operated in separator mode and efficiently suppresses correlated background from the moderator.
Decreasing the temperature takes a very long time! What is going on?
Have you set a value for demand temperature ramping (ramping for short)? If yes, this might be the reason. If you are NOT using LEM autorun, just switch ramping off or do not complain!
If you are using LEM autorun, in principle it should work for reasonable rampings (1-2 K/min). For details see LEM Auto Run Sequence : a description of the LEM Auto Run Sequence, section "Implementation of Set Sample Temperature and the Temperature Monitoring during a Run"
How to abort an Autorun?
Press on the 'Stop AutoRun' botton on the autorun page. If this is done while changing temperature, there is a good chance that on of the valves BPVX/Y is still closed, so better check it!
An autorun started a run but there are no events, what is wrong?
No events typically means: closed valves! In case of the low energy muon apparatus there are several valves/beam blockers which might be closed. There are two beam blockers KV61, KV62 (the main beam blocker of the muE4 beamline) which could be closed. In the low energy apparatus, there are two gate valves (called BPVX and BPVY) which are separating the vacuum chambers (BPVX is separating the moderator chamber from the trigger chamber, and BPVY the trigger chamber from the sample chamber). To open KV61, KV62, either go down to the entrance door of the muE4 area where you will find two switches for the two beam blockers. They can be opened remotely via the beamline frontend. The BPVX/Y can be opened remotely via the LEMVAC frontend.
How to start muE4 beam line control?
On either pc8581 or pc7962, enter beamline in a terminal to start beam line control. Current best settings for LE-uSR are:
WSXon_30Jun2007_300kV_0-99p_piE5-106MeVc.set.
In 11/2006 and spring 2007:WSXon_13Oct2006_300kV_scale099.set.
In 09/2006 and 10/2006: WSXon_18Sep2006_300kV_scale099.set.
In 2005 and spring 2006: WSXon_tune_609-612_300kV_scale099.set.
For low-intensity tests:
WSXoff_v20-3_300kV_0-99p.set
These files can be loaded by pressing the 'Load' button. '0.99p' corresponds to a beam momentum of 27.72 MeV/c.
How to switch on muE4 beam power supplies remotely?
This can be done from the web interface by restarting the beamline slow control frontend:
- press the 'Programs' button on the Midas status page
- press the 'Stop BeamLine SC' button
- wait a few seconds, then press 'Start BeamLine SC'
How to set LE-mu transport potentials (HV's)?
On either pc8581, pc7962, or pc7776:
- double click on the 'hvEdit' icon on the KDE/Windows desktop. In section 'FUG' the transport and sample HV settings can be set. Default settings can be loaded.
- it is possible to start the hvEdit GUI manually as well. In a terminal enter
hvEdit -e nemu -h lem00 &
How to determine the LE-mu implantation energy?
The implantation energy is automatically calculated by the nemu_analyzer and is also written to the run summary file
![\[ \mathrm{E}_{\rm Imp} = \mathrm{Moderator\_HV} - \mathrm{Sample\_HV} - \Delta\mathrm{E(TD)} \]](form_2.png)
where 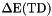 is the energy loss of the muons in the carbon foil of the so-called 'Trigger-Detector' (TD).
is the energy loss of the muons in the carbon foil of the so-called 'Trigger-Detector' (TD).
The energy loss for different Moderator_HV's in the 2.6ug/cm2 TD foil (2008-...) is given in elog:LEM_Experiment/4047.
The energy loss for different Moderator_HV's in the 2.2ug/cm2 TD foil (2003-2007) is given in elog:LEM_Experiment/1535.
How to restart beamline power supplies manually?
It may happen that due to electric noise an interlock of a power supply becomes active. In this case, you have to go to the power supply gallery and do the following steps:
- Switch power supply to local ("Lokal")
- switch off control electronics
- wait a few seconds, switch on control electronics; all interlocks should be off now; if not, there might be a real problem
- switch on "Gleichrichter"
- set back to remote mode ("Fern")
What are 'normal' detector and event rates?
For 2013, 4-cm target E, muE4_20130518.set settings (new EPICS control),
- Spin-rotator (SR) installed; 1-mm thick Ti sample tubes for WEW and Bpar
- 15kV, Ar/N2 moderator 230/14 AA, Ar deposited at 2x10-6 mbar, N2 at 2x10-7 mbar
- e+MCP1 (PosM1): 90k/mAs
- LE-uSR event rate:
860/mAs WEW magnet, APD spectrometer with carbon fibre support, SR -10°
(910/mAs with small sample plates, Konti-4);
460/mAs B-parallel magnet (new APD spectrometer), SR -45°
430/mAs B-parallel magnet (new APD spectrometer), SR -10°
For 2012, 4-cm target E, WSXon_30Jun2007_300kV_0-99p_piE5-106MeVc.set settings,
- Spin-rotator (SR) installed; 2-mm thick Ti sample tubes for WEW and Bpar
- 15kV, Ar/N2 moderator 230/14 AA, Ar deposited at 2x10-6 mbar, N2 at 2x10-7 mbar
- e+MCP1 (PosM1): 88k/mAs
- LE-uSR event rate:
830/mAs WEW magnet, APD spectrometer with carbon fibre support, SR -10°
380-420/mAs B-parallel magnet (original bulky positron counters), SR -10°
450-500/mAs B-parallel magnet (original bulky positron counters), SR -45°
For 2011, 4-cm target E, WSXon_30Jun2007_300kV_0-99p_piE5-106MeVc.set settings,
- e+MCP1 (PosM1): 88k/mAs (after changing detector HV)
- since run 1418, L2 limited to 6kV:
LE-uSR event rate: about 500/mAs for WEW APD-spectrometer with carbon fibre support, Ti sample tube
about 260/mAs B-parallel magnet, stainless steel tube
15 kV, Ar/N2 moderator - before Run 1353, L2 limited to 10.2kV:
LE-uSR event rate: about 560/mAs for WEW APD-spectrometer with carbon fibre support, stainless steel tube (about 650/mAs with Ti sample tube)
300/mAs B-parallel magnet
14 kV, Ar/N2 moderator
For 2010, 4-cm target E, WSXon_30Jun2007_300kV_0-99p_piE5-106MeVc.set settings,
- MCP1: unstable...
- e+MCP1: 76k/mAs
- LE-uSR event rate: about 500(320)/mAs for B-perpendicular (APD spectrometer)/(B-parallel), 15kV, Ar/N2 moderator
For 2009, 4-cm target E, WSXon_30Jun2007_300kV_0-99p_piE5-106MeVc.set settings,
- MCP1: 91k/mAs
- e+MCP1: 81k/mAs (higher than last year because of changed HV for PosM1_I)
- LE-uSR event rate: about 600(320)/mAs for B-perpendicular(B-parallel), 15kV, Ar/N2 moderator
For 2008, 4-cm target E, WSXon_30Jun2007_300kV_0-99p_piE5-106MeVc.set settings,
- MCP1: 100k/mAs
- e+MCP1: 57k/mAs
- LE-uSR event rate: about 290/mAs for Bparallel, 15kV, Ar/N2 moderator
From Sep 2007 on, 4-cm Target E, WSXon_30Jun2007_300kV_0-99p_piE5-106MeVc.set settings (after centering p-beam on target, piE5 momentum set back to 28MeV/c):
- MCP1: 96k/mAs
- e+MCP1: 62k/mAs
- LE-uSR event rate: about 210/mAs for Bparallel, 15kV, N2 moderator
For June/July 2007, 4-cm Target E, WSXon_30Jun2007_300kV_0-99p_piE5-106MeVc.set settings (after centering p-beam on target):
- MCP1: 101k/mAs
- e+MCP1: 62k/mAs
- LE-uSR event rate: about 390/mAs for Bperp, 15kV, N2 moderator
For spring 2007, 4-cm Target E, WSXon_13Oct2006_300kV_scale099.set settings (after muE4 repair):
- MCP1: 83k/mAs
- e+MCP1: 62k/mAs
- LE-uSR event rate: about 190/mAs for Bpar, 15kV, N2 moderator
- LE-uSR event rate: about 230/mAs for Bpar, 20kV, N2 moderator
For autumn 2006, 4-cm Target E, WSXon_13Oct2006_300kV_scale099.set settings:
- MCP1: 83k/mAs
- e+MCP1: 73k/mAs
- LE-uSR event rate: about 190/mAs for Bpar, 15kV, N2 moderator
Note: If you recognize a drop of the LE-uSR event rate by about 20% it is most probably caused by a switch of the proton beam from SINQ to beam dump!!! The maximum proton currents for operation on beam dump are
- 1.7 mA, 4.0-cm target E
- 1.9 mA, 6.0-cm target E
Which E-target was used in LE-uSR runs?
- 2012: 4.0-cm target
- 2011: 4.0-cm target
- 2010: 4.0-cm target
- 2009: 4.0-cm target
- 2008: 4.0-cm target
- 2007: 4.0-cm target E until run 1147, 15/07/2007
6.0-cm target E run 1148 -1569, 27/08/2007
4.0-cm target E later - 2006: 6.0-cm target E until run 878, 21/06/2006
4.0-cm target E later - 2005: 4.0-cm target E
- 2003: 6.0-cm target E
- 2002: 6.0-cm target E ??
- 2001: 4.0-cm target E until run 1356 Wed, 24/Oct/2001 (LB36/77)
6.0-cm target E, starting with run 1364, Fri 26/Oct/2001 (LB37/42)
How do LEM rates change as a function of p-beam position on Target E?
- check this elog entry
- check this elog entry for MCP1 and Pos_M1 rates.
How do the LEM beam spot and alpha parameter change as a function of RA steering?
- check this elog entry
How to start/recover/stop the Midas system?
Login to lem00.
- To start Midas: enter nemu_start_midas
- To stop/recover Midas:
- If Autorun is active: Stop Autorun via the 'Programs' button on the web interface
- If a Run is active: Stop Run via the 'Stop' button on the web interface
- enter nemu_mcleanup to stop Midas.
- enter nemu_start_midas if you want to restart Midas.
How to restart a single Midas client?
All clients can be stopped via the 'Programs' page of the web interface. If stopping fails, goto How to kill a single hanging Midas process?. To restart a client, login to lem00 and enter
[nemu@lem00 nemu]$ nemu_start_midas
(the most, but not all clients can be started as well on the 'Programs' page of the web interface. The use of nemu_start_midas is the safest way to do).
How to kill a single hanging Midas process?
If the process is still running, try to quit it via the 'Programs' page of the web-interface. If it cannot get stopped that way (error message like: Cannot shut down client "HV Detectors", please kill manually and do an ODB cleanup) kill it manually, which works the following: on the DAQ machine enter the linux command ps aux | grep proc_name where proc_name is the hanging process. You will get a list like
nemu 6589 0.7 2.5 25204 22692 ? S Feb13 33:12 mhttpd -p 80 -e nemu -D nemu 6606 0.0 0.5 6276 4576 ? S Feb13 0:00 vme_fe -D nemu 6612 0.0 0.3 4800 2868 ? S Feb13 0:48 lemvac_scfe -D nemu 6620 0.0 0.2 4828 2228 ? S Feb13 2:17 hv_fug_scfe -D nemu 6636 0.0 0.2 4836 2204 ? S Feb13 1:31 sample_scfe -D nemu 6640 0.0 0.2 4828 2248 ? S Feb13 1:28 mod_cryo_scfe -D nemu 6648 0.0 2.9 58012 26880 ? S Feb13 0:00 nemu_analyzer -l -D
the second number is the process id (PID), e.g. 6612 is the PID of the process lemvac_scfe. To kill it enter: kill -9 6612. This should kill the process, yet the process will not have disappeared from the Midas system. Therefore you have to perform a cleanup command in the odbedit.
How to recover the Midas history and Message system?
It may happen, that the Midas history and the Midas message system (with elog) is no longer available at the web interface. The safest way to solve the problem is to execute the recover procedure as described in How to start/recover/stop the Midas system?.
Also, you can do it manually if a run is stopped!!!:
- login to lem00
- [nemu@lem00 nemu]$ killall -9 mhttpd
- [nemu@lem00 nemu]$ odbedit
- [lem00:Nemu:S]/> cleanup
- [lem00:Nemu:S]/> sh logger
- [lem00:Nemu:S]/> exit
- [nemu@lem00 nemu]$ rm /mnt/data/nemu/history/*.idx
- [nemu@lem00 nemu]$ rm /mnt/data/nemu/history/*.idf
- [nemu@lem00 nemu]$ nemu_start_midas (this will start mlogger and mhttpd)
A slow control frontend connected to the RS232 terminal server does not to respond even after restart. What can I do?
If the process is still running, try to quit it via the 'Programs' page of the web-interface. If it cannot get stopped that way (error message like: Cannot shut down client "HV Detectors", please kill manually and do an ODB cleanup) kill it manually (How to kill a single hanging Midas process? ). If you have stopped the process check the status of the RS232 terminal server. This is done the following way: enter the url of the RS232 terminal server in a web-browser (psts03). There you will see a list of all the services running on the RS232 terminal server. Check the status of your device: the port should be 'available', if it is still connected, the RS232 terminal server is blocking the port. In this case you have to logout this port (see How to logout a blocking port at the RS232 terminal server? )
How to logout a blocking port at the RS232 terminal server?
Open a telnet session on the RS232 terminal server (e.g. telnet psts03). At the prompt Username> enter s another prompt will show: Local_34>. At the new prompt you enter the command su. The RS232 terminal server will ask you for the password (see How to change a Sample? ); enter it and the prompt will change to Local_34>>. Now you can enter the logout command logout port x, where x is the port number. The port number is a number between 1 and 32. To logout and quit the telnet session enter logout.
How to check an MSCB line without Midas?
The program msc -d mscbxxx, where xxx is the number of the MSCB line to be checked, can be used to address, scan, and manipulate MSCB nodes. It is a command line driven tool. Once connected to a MSCB line, entering help gives you the list of the available commands.
How to deal with a hanging MSCB submaster?
Check if you can ping the MSCB submaster (the ping command is stopped by CTRL-C). If the submaster is OK you get something like
[nemu]$ ping mscb007 PING mscb007.psi.ch (129.129.140.193) 56(84) bytes of data. 64 bytes from MSCB007.psi.ch (129.129.140.193): icmp_seq=0 ttl=64 time=1.87 ms 64 bytes from MSCB007.psi.ch (129.129.140.193): icmp_seq=1 ttl=64 time=2.26 ms 64 bytes from MSCB007.psi.ch (129.129.140.193): icmp_seq=2 ttl=64 time=1.98 ms 64 bytes from MSCB007.psi.ch (129.129.140.193): icmp_seq=3 ttl=64 time=1.88 ms
if it is not reachable it will look like this
[nemu]$ ping mscb006 PING mscb006.psi.ch (129.129.140.197) 56(84) bytes of data. From lem00.psi.ch (129.129.140.143) icmp_seq=0 Destination Host Unreachable From lem00.psi.ch (129.129.140.143) icmp_seq=1 Destination Host Unreachable From lem00.psi.ch (129.129.140.143) icmp_seq=2 Destination Host Unreachable
--- mscb006.psi.ch ping statistics --- 5 packets transmitted, 0 received, +3 errors, 100% packet loss, time 4048ms , pipe 4
If the submaster is pingable, check the particular line with msc (see How to check an MSCB line without Midas? ), if it is OK, restarting the submaster should be working. If you cannot find anything with a msc-scan, the MSCB hardware modules need to be checked!
If the submaster is not pingable it needs to be repowered, this can be done remotely using lemplug (see How to remotely repower some of the slowcontrol equipment using lemplug? ). After repowering the MSCB submaster, wait a few seconds (the submaster needs first to get a new IP address, etc.), than repeat the whole proceedure (ping, msc-scan, ...).
How to remotely repower some of the slowcontrol equipment using lemplug?
Part of the slowcontrol equipment is the lemplug (for details see Slowcontrol ). The slowcontrol process for the lemplug device (Leunig ePowerSwitch M8) is running on the DAQ PC in a separate experiment 'lemplug' (see lemplug). The lemplug is a remotely switchable power outlet with 8 independent 230V outlets. The corresponding channels in the slowcontrol equipment are self-explanatory.
How to remotely set the needlevalve of the transferline?
The transferlines of the Konti-cryostats have equipped with a steppermotor for remote setting. On the status page of the SampleCryo (see Slowcontrol for details) one finds at the end of the input variables the needlevalve readback. The unit is %. If the value is -300 then the front_end for the steppermotor is not running or a wrong read_back_device is in the database. If the value is < -500 then the reading is out of range, probably the lemo-plug (yellow) in the top of the motor has been removed (for sample or dewar change ?) or the SCS900 is not working. Values between 0 - 100 % are OK. At very low temperature a value of 10 - 90 is possible, above about 20 K something like 3-5 % should be the correct value. The needlevalve can be set on the botton part of the status page. The next value is the modus of the transferline steppermotor: 0 means only read_back, 1 means raed_back and setting from this page, while 2 means that autorun can set the needlevalve. The needlevalve can always be moved manually, the software keeps track. If one tries to set the valve while the cables are removed a warning will be issued. Setting of the valve should be such that the Bronkhorst flow regulator can do its job: that is the pressure should be not much higher than 0.9 barr (to maintain a pressure gradient over the transferline) and the valve position of the Bronkhorst should be between 0 and 1, otherwise the Bronkhorst is out off its regulation range. Autorun is using these criteria to update the needelvalve setting if it is allowed to do so.
Some good starting values for the needlevalve are:
| Temperature (K) | NeedleValve (%) |
|---|---|
| 4.0 | 60 |
| 5.0 | 20 |
| 8.0 | 10 |
| 12.0 | 7 |
| 15.0 | 5 |
| 20.0 | 4 |
| >20.0 | 4 |
How to view LE-uSR runs?
On either pc8581 or pc7962, run LEMu (case sensitive) from the bash shell.
- choose the run number and the year.
- check/uncheck the boxes "up-down", and "ppu rejection". ppu stands for postpileup (whats that?)
- type in the values for t0 for both detectors. (see: From where do I get the t0's? )
- click "Add Run".
- If you want to plot the sum of more the a single run, return to the beginning.
- set alpha. for TF data, set alpha to zero for a fit. Note: alpha here is N0_l / N0_r (opposite to WKM)
- choose a color for plotting.
- to add the loaded run(s) to an existing canvas, click "Add to plot". To plot on a new canvas, click "Plot New".
The plot canvas is divided to three parts: 1) run title, as taken from the root file. 2) Left (up) detector asymmetry. 3) Raw histograms. For the Asymmetry part:
-
raw histograms are rebinned, and then fit to
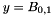 (from t=11.8 microsec to end ~12.2microsec), where 0,1 are L,R or U,D.
(from t=11.8 microsec to end ~12.2microsec), where 0,1 are L,R or U,D. -
alpha is taken from the GUI / calculated (alpha = 0) in the following manner:
The asymmetry is calculated with alpha=1 according to the next line. Then, it is fit to y = p, to find its "baseline". p is related to alpha via![\[ \alpha = \frac{1+p}{1-p} \]](form_5.png)
-
The asymetry is calculated with:
![\[ A_{raw}(t) = \frac{ (N_0(t)-B_0)-(N_1(t)-B_1) } {(N_0(t)-B_0)+(N_1(t)-B_1)} \]](form_6.png)
The errors in A(t) are calculated using the linearly-independent error propagantion formula.![\[ A(t) = \frac{(\alpha-1)-(\alpha \beta + 1) \times A_{raw}(t)}{(\alpha \beta - 1) \times A_{raw}(t)-(\alpha +1)} \]](form_7.png)
How to convert LE-uSR data for WKM, MaxEnt, Wimda?
On either pc8581 or pc7962, run in terminal:
- roothisto2nemu online will convert the histograms of the active run to .nemu format
- roothisto2nemu -rebin 5 online will rebin by 5 the online histograms and save the data in .nemu format
- roothisto2nemu <RunNr> will convert histograms of a finished run.
- roothisto2nemu without parameters will give online help
Where are the data files?
On either pc8581 or pc7962, data files are available in
- /mnt/data/nemu/summ/2007 contains run summary files with all important run parameters
- /mnt/data/nemu/wkm/2007 contains the converted .nemu files for year 2007
- /mnt/data/nemu/his/2007 contains the 'raw' root histogram files
Where are the input files for WKM and MaxEnt?
On either pc8581 or pc7962, these files are available in
- /mnt/home/nemu/analysis/WKM/2006/ for WKM, 2006 data
- /mnt/home/nemu/analysis/maxent/2006/ for MaxEnt, 2006 data
From where do I get the t0's?
A printout is in the LEM counting room. Electronically, they are saved in the LEM elog
- for Apr-... 2008, check this elog entry.
- for Aug-Dec 2007, check this elog entry.
- for Apr-Jul 2007, check this elog entry.
- for Sep-Dec 2006, check this elog entry.
- for Apr-Jul 2006, check this elog entry.
- for Oct-Dec 2005, check this elog entry.
- for 1998 - 2003, check this elog entry.
From May-2007 on they are calculated automatically by the program nemu_analyzer and updated in the Online Data Base (ODB) in /Info/t0_parameter, and written to the histogram run header as well as to the summary files. The following elog entries address the basics of t0 calculation:
- t0/TOF scaling
- t0 scaling, RA-off
- energy loss in TD detector, 2.6ug/cm2 foil.
- energy loss in TD detector, 2.2ug/cm2 foil.
What is the time resolution of the TDC?
- Since 2005: one bin in LE-uSR raw histograms corresponds to 195.3125ps (== 1/160MHz/32).
- Before 2005: one bin in LE-uSR raw histograms corresponds to 1ns.
How can WKM read *.root files?
WKM can read read *.root files by setting the type to ROOT and the format to NEMU, e.g.
RUN lem07_his_1000 ROOT NEMU in the *.msr file.
If one want to read the postpileup data then one should use ROOT20 as a type, e.g.
RUN lem07_his_1000 ROOT20 NEMU in the *.msr file.
How to estimate alpha, how to check goodness of data?
A root macro getAlpha.C can be used for checking alpha's and goodness of data at low implantation energies and early times (t-t0 < 100ns). A detailed explanation on howto use and how it works can be found here.
How to program the CFD950?
Check this elog entry.
